Data Structures Quick Reference
Data structures are the building blocks of efficient software. Choosing the right structure for your problem can mean the difference between a system that scales gracefully and one that collapses under load. This comprehensive guide covers the essential data structures every engineer needs to understand—from fundamental arrays and linked lists to sophisticated trees and graphs—equipping you to make informed architectural decisions that optimize both performance and maintainability.
Linear Data Structures
Linear structures organize data sequentially, where each element has a clear predecessor and successor. Arrays provide lightning-fast random access through contiguous memory, while linked lists excel at dynamic insertion and deletion. Stacks and queues enforce specific access patterns (LIFO and FIFO) that naturally model real-world scenarios like function calls, task scheduling, and undo operations. Understanding these fundamentals is critical—they form the foundation for more complex structures and appear everywhere in production systems.

Array
Parking Lot
Like a parking lot with numbered spaces where you can drive directly to space #5 without passing through 1-4.
Fixed-size collection of elements stored in contiguous memory locations – offers constant-time random access by index.
- O(1) random access by index
- Fixed size in most languages
- Cache-friendly contiguous memory
- O(n) insertion/deletion in middle

Dynamic Array (List)
Expandable Suitcase
Like an expandable suitcase that automatically grows when you pack too much, providing flexible capacity.
Resizable array that grows automatically when capacity is reached – balances array benefits with dynamic sizing.
- O(1) amortized append operation
- Automatic resizing when full
- O(1) random access by index
- Slight overhead for capacity management
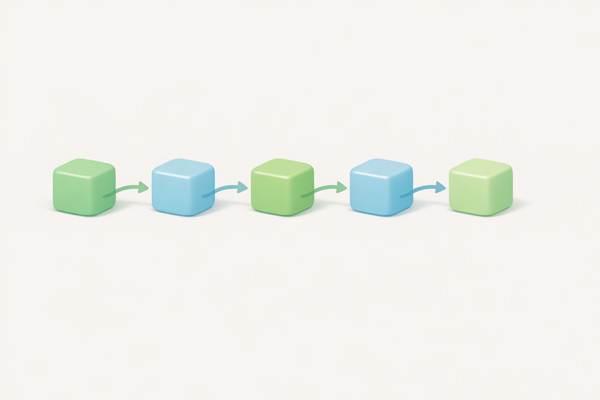
Linked List
Train Cars
Like train cars connected by couplings, where each car points to the next, making it easy to add or remove cars.
Chain of nodes where each node contains data and a reference to the next node – enables efficient insertion and deletion.
- O(1) insertion/deletion at known position
- O(n) access by index
- Dynamic size without reallocation
- Extra memory for node pointers
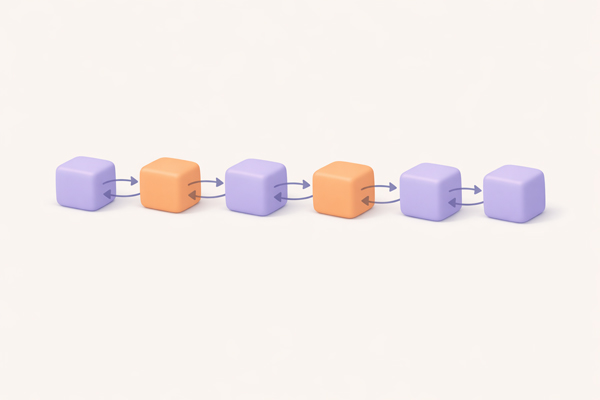
Doubly Linked List
Subway Cars
Like subway cars where you can walk forward or backward through connected cars with doors at both ends.
Linked list where each node has references to both next and previous nodes – allows bidirectional traversal.
- Bidirectional traversal
- O(1) deletion with node reference
- More memory per node (two pointers)
- Easier to implement certain operations

Stack
Stack of Plates
Like a stack of plates where you only add or remove from the top – last in, first out (LIFO).
LIFO (Last In, First Out) data structure with push and pop operations – used for function calls, undo operations, and expression evaluation.
- O(1) push and pop operations
- LIFO ordering principle
- Function call stack
- Backtracking algorithms

Queue
Checkout Line
Like a checkout line at a store where the first person to arrive is the first to be served – first in, first out (FIFO).
FIFO (First In, First Out) data structure with enqueue and dequeue operations – used for task scheduling and breadth-first search.
- O(1) enqueue and dequeue
- FIFO ordering principle
- Task scheduling and buffering
- Breadth-first traversal
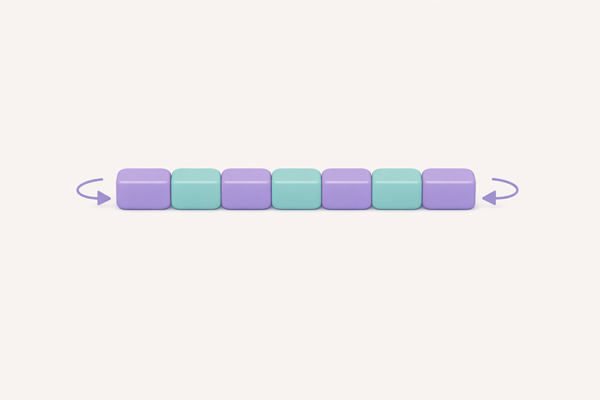
Deque (Double-Ended Queue)
Double-Ended Ticket Line
Like a ticket window with entrances at both ends, allowing people to join or leave from either side.
Queue with insertion and deletion at both ends – combines stack and queue capabilities in one structure.
- O(1) operations at both ends
- Can act as stack or queue
- Sliding window algorithms
- Flexible insertion/removal
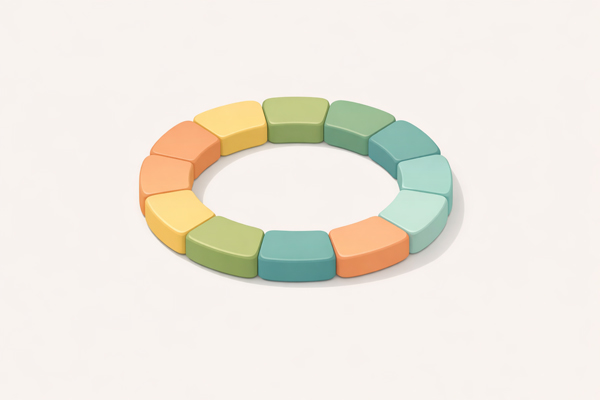
Circular Buffer (Ring Buffer)
Carousel
Like a carousel that wraps around to the beginning after reaching the end, continuously cycling through positions.
Fixed-size buffer where the end connects to the beginning – overwrites oldest data when full, ideal for streaming data.
- Fixed memory allocation
- Constant-time operations
- Automatic overwrite when full
- Streaming data and logging
Tree Data Structures
Trees model hierarchical relationships where data branches out from a root, enabling efficient searching, sorting, and organization. Binary search trees provide O(log n) operations when balanced, making them ideal for dynamic sorted collections. Self-balancing variants like AVL and Red-Black trees maintain optimal performance automatically, while specialized trees like B-trees power database indexes and heaps enable priority queues. Tries optimize string operations for autocomplete and spell-checking. Mastering trees unlocks powerful algorithmic techniques for organizing and retrieving data at scale.
Binary Tree
Family Tree
Like a family tree where each person has at most two children, forming a hierarchical structure.
Hierarchical structure where each node has at most two children (left and right) – foundation for many tree-based structures.
- Each node has max 2 children
- Recursive structure
- Various traversal methods
- Foundation for BST and heaps
Binary Search Tree (BST)
Dictionary
Like looking up words in a dictionary where you go left for earlier words or right for later words at each step.
Binary tree where left children are smaller and right children are larger – enables efficient searching, insertion, and deletion.
- O(log n) average case operations
- Left < Node < Right property
- In-order traversal gives sorted data
- Can degrade to O(n) if unbalanced
AVL Tree
Balanced Scales
Like balanced scales that automatically adjust weights to stay level, maintaining perfect balance at all times.
Self-balancing BST that maintains height difference of at most 1 between left and right subtrees – guarantees O(log n) operations.
- Strictly balanced tree
- O(log n) guaranteed operations
- Rotation to maintain balance
- More rotations than Red-Black
Red-Black Tree
Traffic Rules
Like traffic rules with color-coded signals ensuring smooth flow by maintaining strict but flexible balance properties.
Self-balancing BST using node colors and rules to maintain approximate balance – used in many standard libraries.
- Color-based balancing rules
- O(log n) operations guaranteed
- Fewer rotations than AVL
- Used in TreeMap, TreeSet

B-Tree
Library Catalog System
Like a library catalog with multiple entries per drawer, optimized for reading large blocks of related data at once.
Self-balancing tree with multiple keys per node – optimized for systems that read/write large blocks of data like databases.
- Multiple keys per node
- Optimized for disk I/O
- Used in databases and filesystems
- Reduces tree height
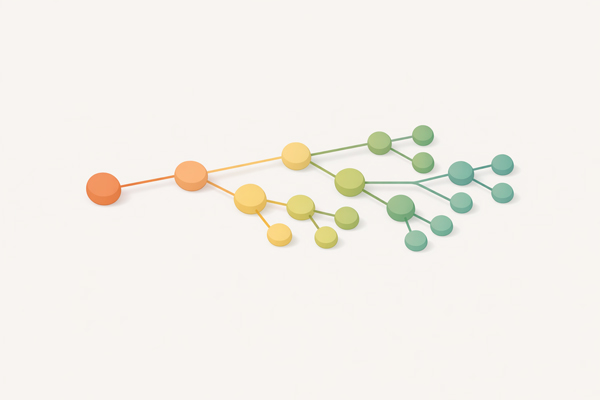
Trie (Prefix Tree)
Autocomplete Suggestions
Like autocomplete that shares common prefixes among words, branching out only where words differ.
Tree where each node represents a character, sharing common prefixes – ideal for string matching and autocomplete features.
- Efficient prefix searching
- O(m) lookup for string length m
- Autocomplete and spell check
- Space-intensive for sparse data
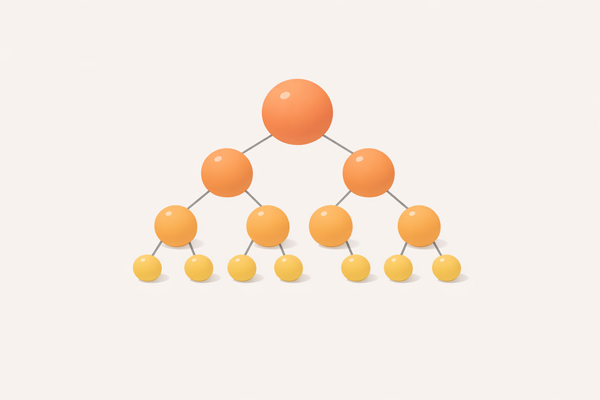
Heap (Priority Queue)
Emergency Room Triage
Like an ER triage where the most critical patient is always seen first, regardless of arrival order.
Binary tree where parent nodes are ordered relative to children – efficiently retrieves minimum or maximum element.
- O(1) peek min/max element
- O(log n) insert and remove
- Used in priority queues
- Heap sort algorithm

Segment Tree
Sports Tournament Statistics
Like tournament brackets tracking cumulative stats, where each level summarizes ranges from the level below.
Tree for storing intervals or segments – allows efficient range queries and updates on arrays.
- O(log n) range queries
- O(log n) range updates
- Sum, min, max queries
- Competitive programming favorite
Hash-Based Data Structures
Hash structures use mathematical functions to map keys directly to storage locations, delivering near-instant lookups. Hash tables (maps) are the workhorses of modern programming—caching, indexing, and deduplication all rely on O(1) average-case access. Hash sets enforce uniqueness while providing constant-time membership testing. Variants like linked hash maps preserve insertion order, while probabilistic structures like Bloom filters trade perfect accuracy for extreme space efficiency. These structures power everything from compiler symbol tables to distributed caches, making them indispensable in high-performance systems.

Hash Table (Hash Map)
Locker Room
Like a locker room where you use your unique combination to instantly find your locker without searching.
Key-value data structure using hash function to compute index – provides near-constant time lookup, insertion, and deletion.
- O(1) average case operations
- Hash function maps keys to indices
- Collision handling required
- Fast lookups and insertions

Hash Set
Club Membership List
Like a club membership list where you can instantly check if someone is a member, with no duplicates allowed.
Collection of unique elements using hash table – efficiently tests membership and prevents duplicates.
- O(1) membership testing
- No duplicate elements
- Unordered collection
- Set operations: union, intersection

Linked Hash Map
Museum Tour Path
Like a museum tour that lets you quickly find exhibits by name while maintaining the order you visited them.
Hash map that maintains insertion order using a linked list – combines fast lookup with predictable iteration order.
- O(1) operations like HashMap
- Maintains insertion order
- Predictable iteration
- LRU cache implementation

Bloom Filter
Spam Filter
Like a spam filter that quickly says "definitely not spam" or "probably spam," trading accuracy for speed and space.
Probabilistic data structure for membership testing – space-efficient but allows false positives, never false negatives.
- Space-efficient membership test
- False positives possible
- No false negatives
- Cannot remove elements
Graph Data Structures
Graphs model complex relationships where any node can connect to any other—think social networks, road maps, or dependency chains. They generalize trees by allowing cycles and multiple paths between nodes. Directed graphs capture one-way relationships like web links and task dependencies, while weighted graphs assign costs to connections for shortest-path algorithms. Representation choices (adjacency lists vs. matrices) dramatically impact performance for sparse vs. dense graphs. Understanding graphs is essential for network analysis, recommendation systems, route planning, and distributed system design.

Adjacency List
Social Network Friends
Like a social network where each person has a list of their friends, efficiently storing who's connected to whom.
Graph representation where each vertex stores a list of adjacent vertices – space-efficient for sparse graphs.
- Space: O(V + E)
- Efficient for sparse graphs
- Fast edge iteration per vertex
- Slower edge existence check

Adjacency Matrix
Flight Route Table
Like an airline route table showing direct flights between all city pairs in a grid, fast to check but space-intensive.
2D matrix representing graph edges – offers O(1) edge lookup but uses O(V²) space regardless of edge count.
- Space: O(V²)
- O(1) edge existence check
- Efficient for dense graphs
- Wasteful for sparse graphs
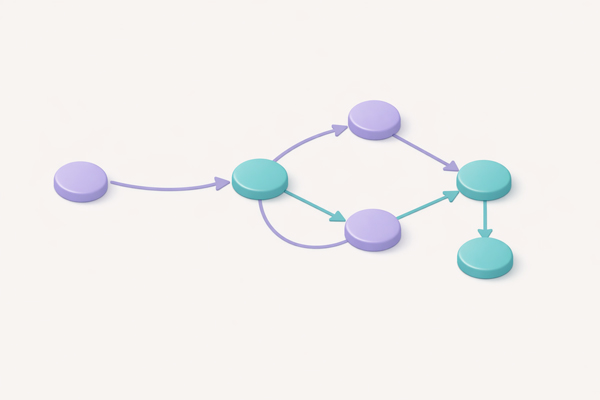
Directed Graph (Digraph)
One-Way Street Map
Like a city map with one-way streets where you can go from A to B but not necessarily back from B to A.
Graph where edges have direction – used for modeling asymmetric relationships like web links, dependencies, and workflows.
- Edges have direction
- In-degree and out-degree
- Topological sorting possible
- Models dependencies

Weighted Graph
Road Map with Distances
Like a road map showing distances between cities, where each connection has a cost or weight associated with it.
Graph where each edge has an associated numerical weight – used for shortest path algorithms and network optimization.
- Edges have weights/costs
- Shortest path algorithms
- Network flow problems
- Dijkstra, Bellman-Ford
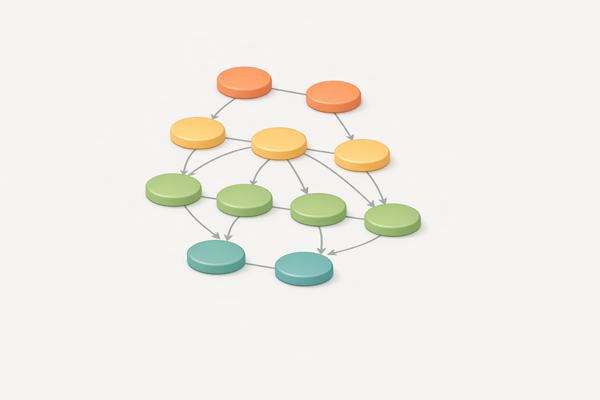
Directed Acyclic Graph (DAG)
Project Task Dependencies
Like a project plan where tasks have prerequisites but no circular dependencies, ensuring a valid completion order.
Directed graph with no cycles – fundamental for task scheduling, build systems, and dependency resolution.
- No cycles allowed
- Topological ordering exists
- Build systems, schedulers
- Git commit history
Specialized Data Structures
Specialized structures solve specific problems with exceptional efficiency that general-purpose structures can't match. Union-Find tracks disjoint sets for network connectivity, LRU caches implement sophisticated eviction policies in O(1) time, and segment trees enable lightning-fast range queries. Skip lists offer probabilistic balancing that's simpler than balanced trees, while suffix trees power advanced string algorithms in bioinformatics. These structures represent decades of algorithmic innovation, each optimized for particular use cases. Learning when to reach for these tools separates expert engineers from those still hammering every problem with arrays and hash tables.
Union-Find (Disjoint Set)
Social Groups
Like tracking friend groups that merge when people introduce their separate circles to each other.
Tracks disjoint sets with efficient union and find operations – used in network connectivity and Kruskal's algorithm.
- Near O(1) operations with optimizations
- Path compression technique
- Union by rank/size
- Kruskal's MST algorithm

LRU Cache
Browser Tab Management
Like browser memory management that closes the least recently used tabs when running out of memory.
Combines hash map and doubly linked list to evict least recently used items – provides O(1) get and put operations.
- O(1) get and put operations
- Automatic eviction policy
- Fixed capacity
- Common in caching systems
Skip List
Highway Express Lanes
Like highway express lanes where you skip multiple exits at higher levels to reach your destination faster.
Multi-level linked list with express lanes – provides O(log n) operations with simpler implementation than balanced trees.
- O(log n) average operations
- Probabilistic balancing
- Easier than balanced trees
- Used in Redis sorted sets

Suffix Tree
Text Search Engine
Like indexing every suffix of a book for lightning-fast searching of any substring within the text.
Compressed trie of all suffixes in a string – enables fast pattern matching and string analysis.
- O(m) pattern searching
- All suffixes indexed
- Complex construction
- Bioinformatics applications
Fenwick Tree (Binary Indexed Tree)
Running Totals Dashboard
Like a dashboard showing cumulative statistics where you can quickly update values and query running totals.
Efficient structure for prefix sum queries and updates – uses binary representation for clever indexing.
- O(log n) update and query
- Space: O(n)
- Simpler than segment tree
- Cumulative frequency tables

Sparse Table
Historical Min/Max Records
Like pre-computed records of temperature ranges for every possible time period, enabling instant lookups.
Precomputed structure for immutable range queries – offers O(1) query time after O(n log n) preprocessing.
- O(1) range min/max query
- Immutable data only
- O(n log n) space and preprocessing
- Idempotent operations